Hello, I am using an Agilent 8890 GC with a 7000D triple quadrupole. I have MassHunter version 10.0 with Quant and Qual software. I am trying to optimize library and compound identification parameters in the Unknowns Analysis Program and Qualitative Analysis program. Specifically I am confused on the RT Match settings. I don't understand the meaning of some of these settings. I don't understand the difference between the RT penalty functions and RT mismatch penalty.
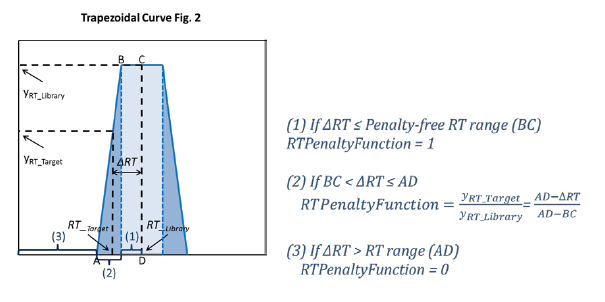
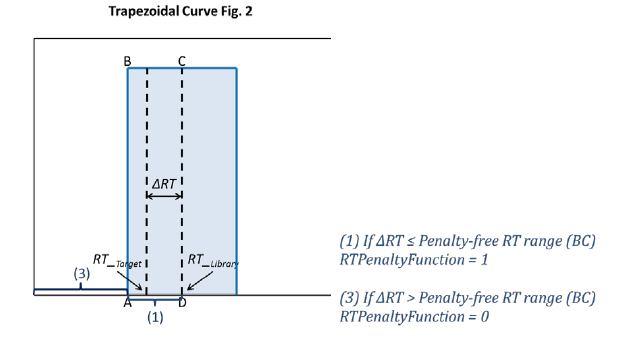
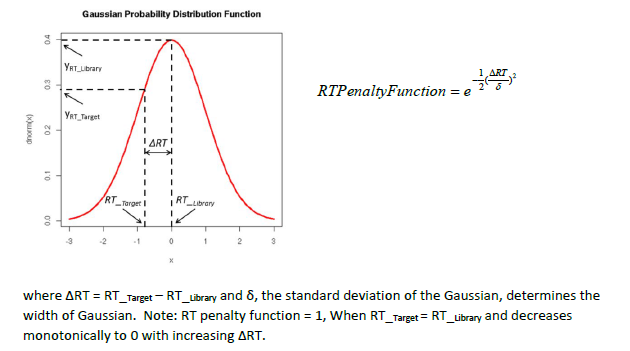
Basically what I want library to do is search my custom user library using RT and spectra. If RT is outside a certain window (5 seconds, 10 seconds, 30 seconds whatever) I want to reject that hit and with NIST. If I ignore RT what happens is my custom library ends up finding the same compounds at multiple retention times which I know are wrong. So I want to use RT to reject these incorrect hits and use NIST to give me an idea what they might be. But these settings are new to me and I can't find clear explanation what they mean in any of the manuals / webinars I've looked at.