

Hello,
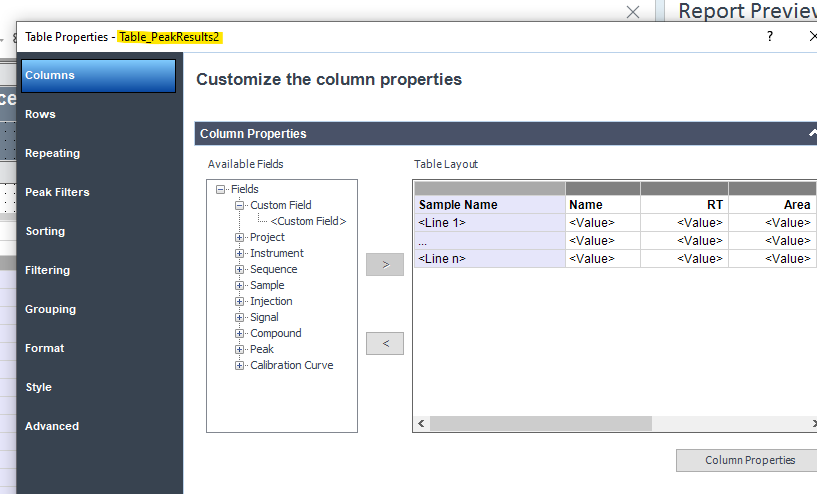
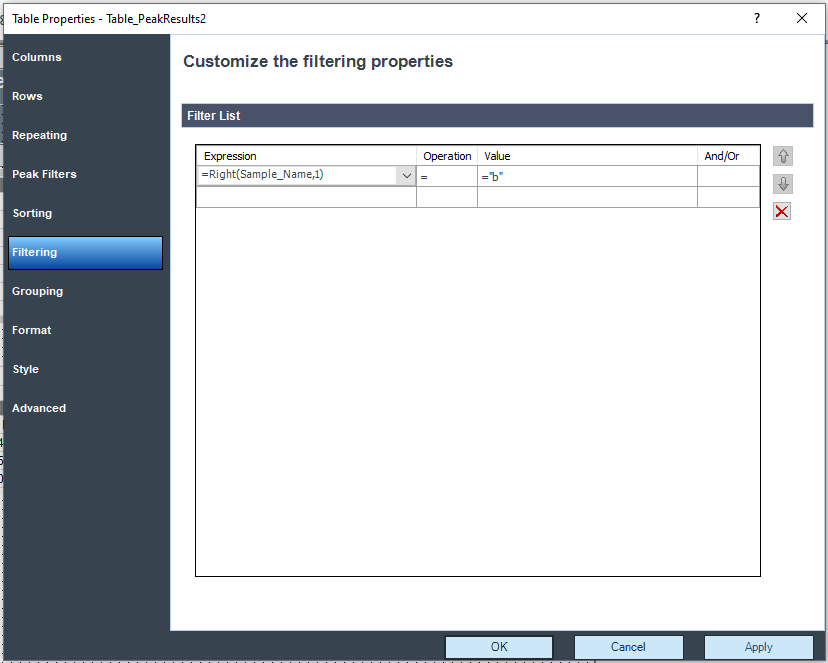
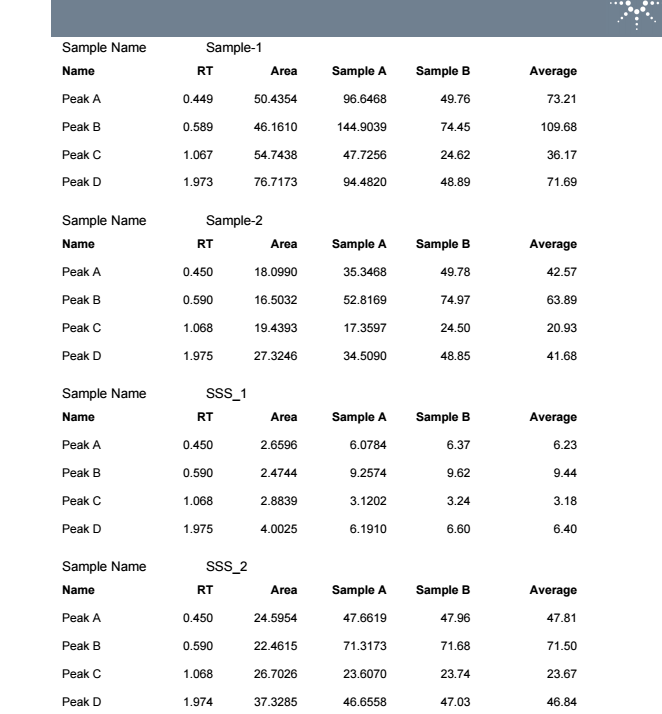
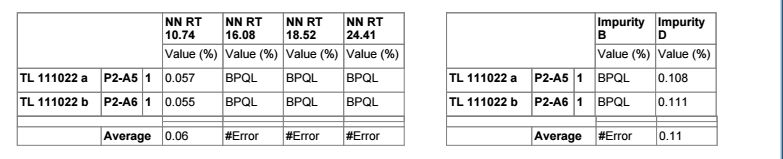
We were trying to create a summarization table at the end of the report. The table that you can see on the screenshot below is created from matrix. BPQL means that the value is lower than 0.045 but OpenLab can’t calculate the average from “text values” so the average value is Error in case of BPQL partial results. Is there any way how to put BPQL into the average row or can we hide the “Error” expression in that table (matrix)?
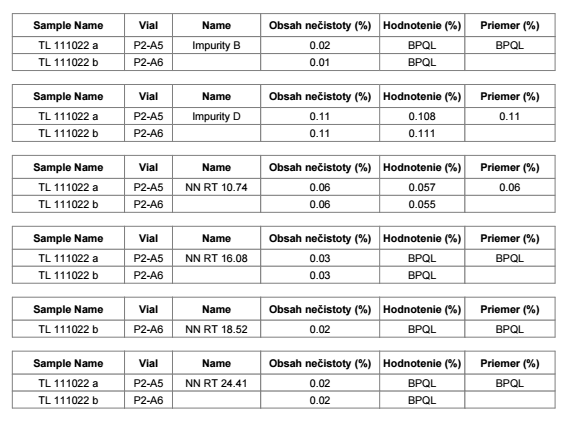
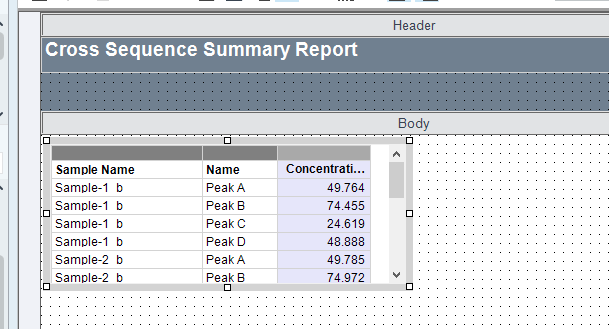
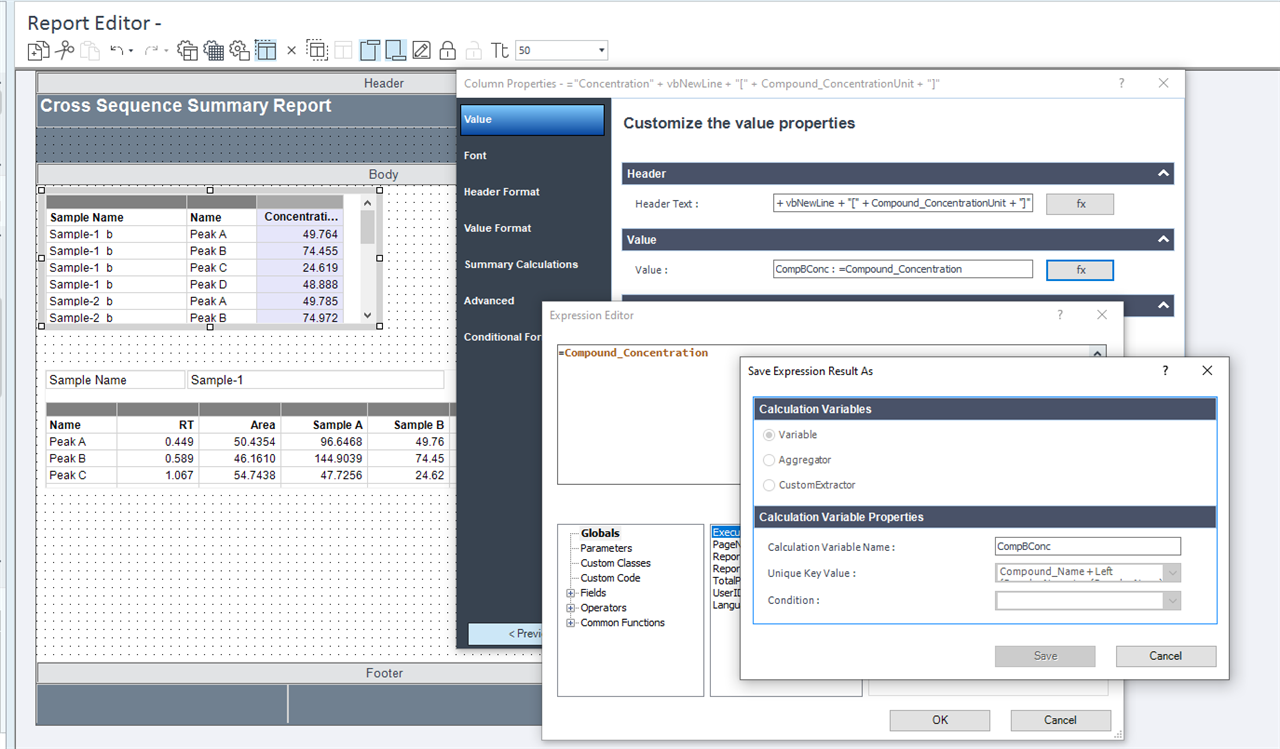
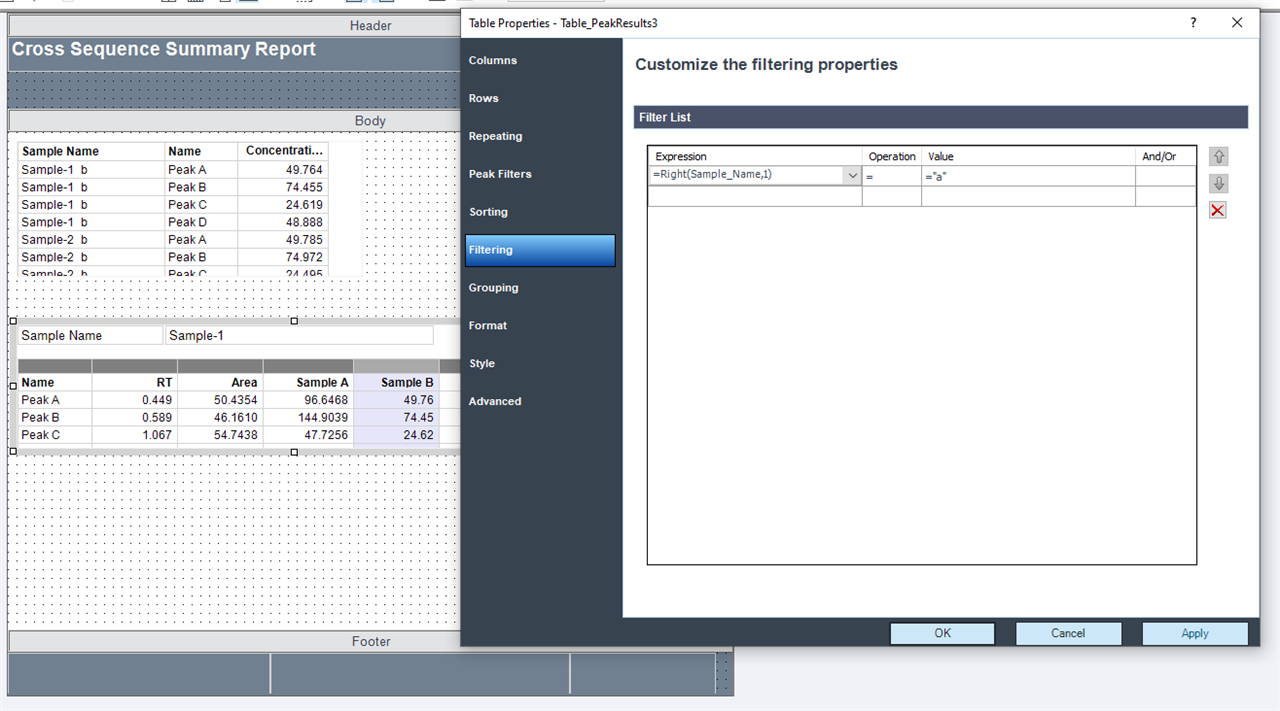
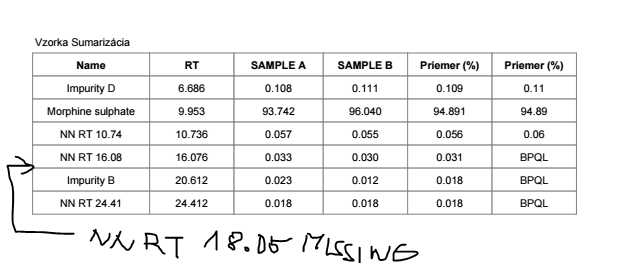
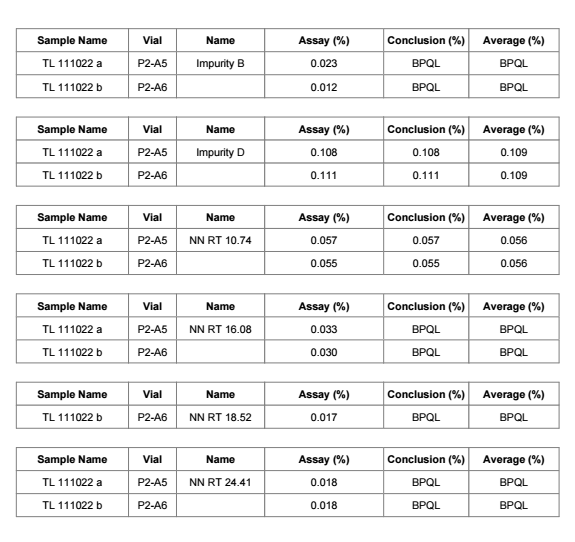
On another screenshot, you can see other try for creation of summarization table. Table is form from Compound result table so it’s more flexible than matrix. For calculating the average, we’re currently using aggregator from hidden table. In this case I just want to ask if it’s possible to get only one result value in average column. Now as you can see in average column, we get the same final results for every impurity. When we hide duplicates, it hides same expression/numbers in that column not just in row. Is there any way how to merge cells for single compound (impurity) in average column to get only one final result (BPQL or number)?
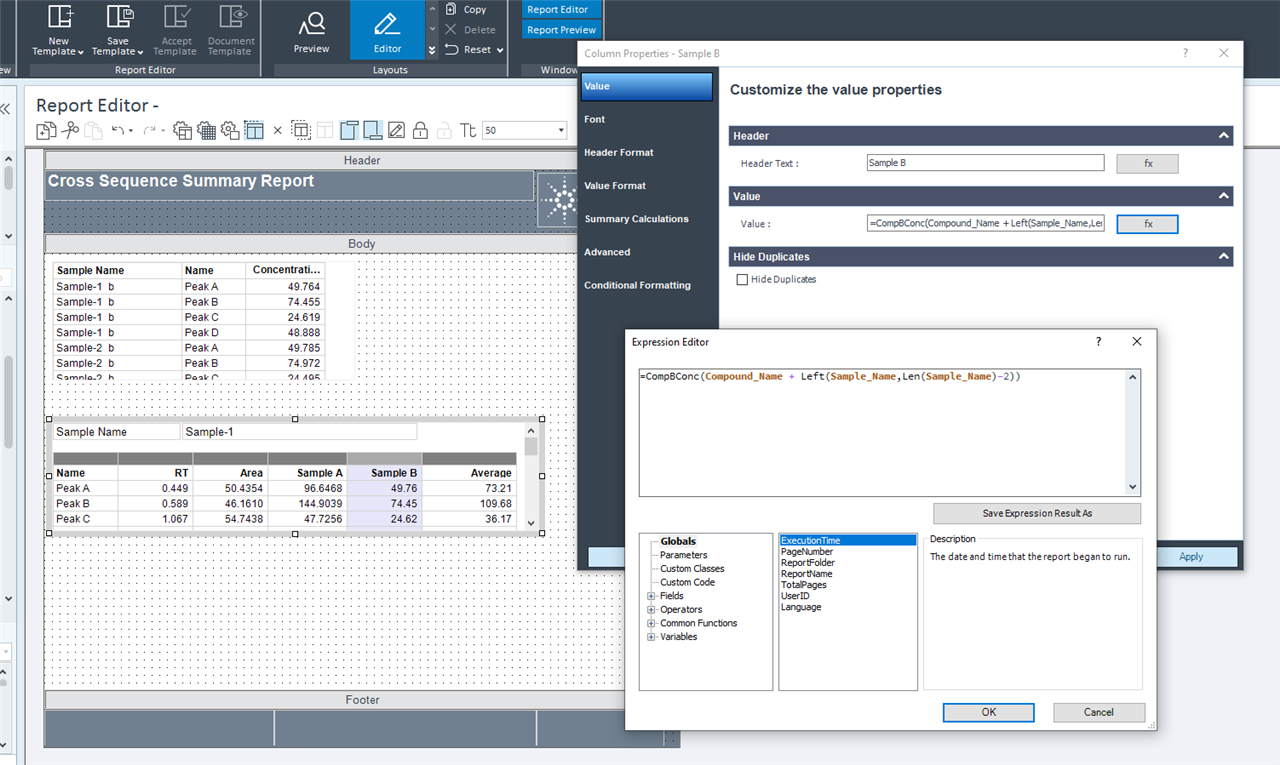
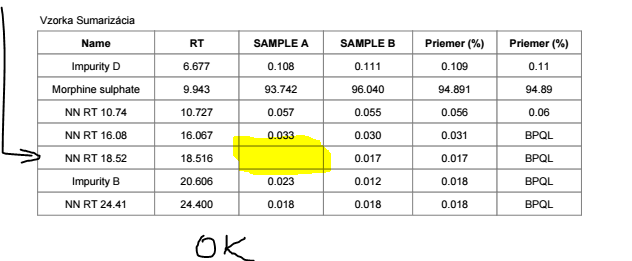
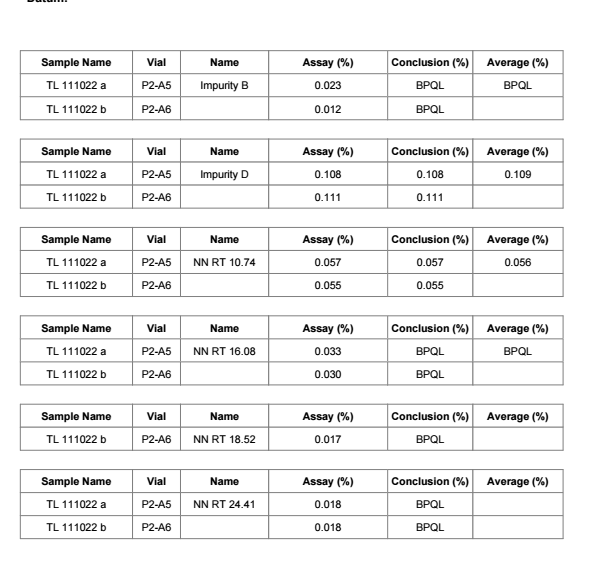
Here you can see the table with hidden duplicates in average column.
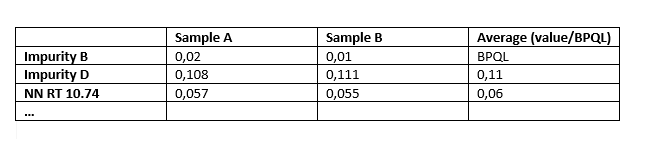
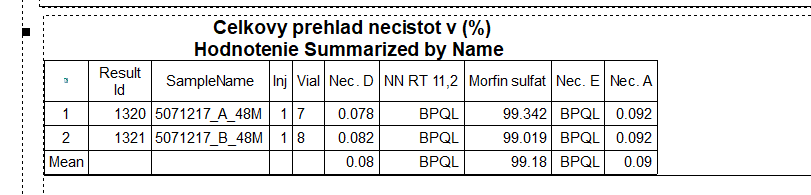
At last we attach the summarization table from EMPOWER. Our goal is to create the same or very similar summarization table in OpenLab. We hope that it is possible  We are currently using OpenLab
We are currently using OpenLab
Thank you very much for your answers.