

Hello all
I am using openlab cds v 2.6
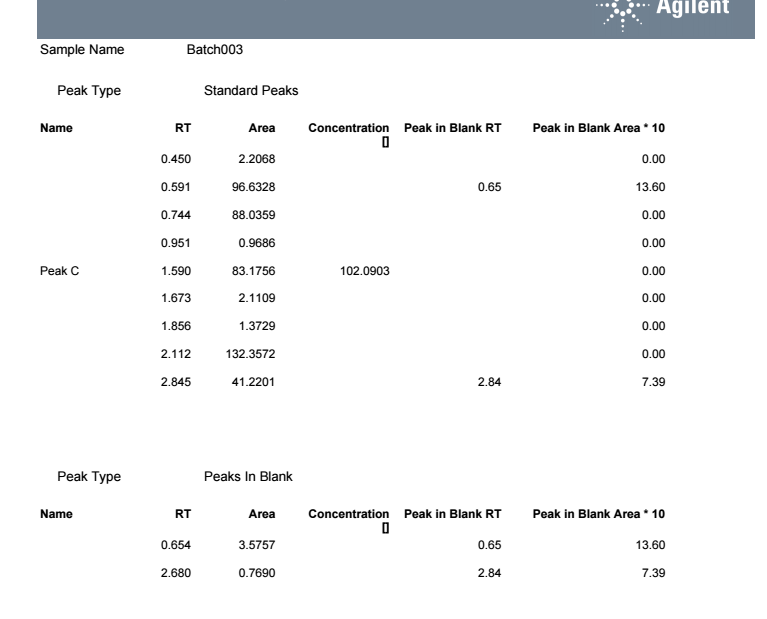
In our company we run a blank followed by samples and a standard. We use standard for quantifying impurities while those peaks that appears in blank are not considered as impurties
Is there any way to eliminate the peaks that appears in blank from samples based on their retention time ?