

Hello
I have a question about grouping in the report template/intelligent reporting in Open Lab CDS 2.5. (what is the difference?)
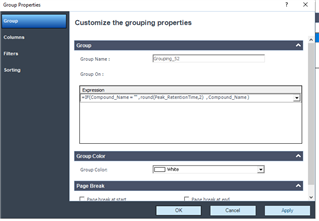
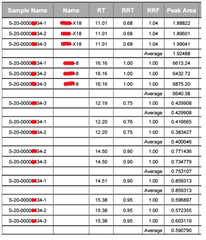
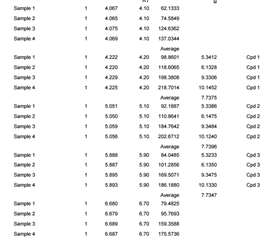
I am currently working on grouping three different injections of the same sample. The grouping parameters i have currently set to this: =IF(Compound_Name = "" , round(Peak_RetentionTime,2) , Compound_Name )
This works perfectly for my named peaks, however when an unknown has a retention time of 0.01 more or less in one of the injections, they are obviously not grouped. How can i change my formula to include RT +/- 0.01